벡터DB와 LLM을 활용한 Q&A 시스템 개발 Case study

들어가며
대규모 언어모델(이하 LLM)이 자연어 처리영역에서 높은 성능을 보이고 있지만, 특정 도메인이나 전문 분야에서는 환각효과와 같은 문제가 발생하고 있습니다. 특히 학습되지 않은 분야에서는 정확한 답변을 할 수 없는데, 예를 들어 로펌에서 보관하고 있는 판례, 슬랙에 저장된 회사 커뮤니케이션과 같은 고유데이터에 대해서는 LLM이 적절한 답변을 제공할 수 없습니다. 회사가 방대하게 축적한 고유데이터를 의미 있게 검색하기 위해서는 LLM만으로 부족한 것이죠.
이러한 문제를 해결하기 위해 벡터데이터베이스(VectorDB)를 대규모언어모델의 장기기억 저장장치로 활용하는 방안이 주목받고 있습니다. 문서, 이미지, 텍스트, 음성 등 모든 종류의 데이터는 벡터데이터(벡터임베딩)로 변환될 수 있는데, 벡터데이터베이스는 이러한 벡터임베딩을 저장하고 검색하기 위한 데이터베이스입니다.
기존의 관계형 데이터베이스(RDB)나 NoSQL 데이터베이스가 데이터 형식에 제약을 받는 것과는 달리, 벡터 데이터베이스는 모든 데이터를 벡터임베딩이라는 통일된 형식으로 처리할 수 있어 효과적인 데이터 관리와 검색이 가능합니다. 그렇다면 벡터데이터베이스를 어떤 방식으로 LLM의 장기기억저장장치로 사용할 수 있을까요?
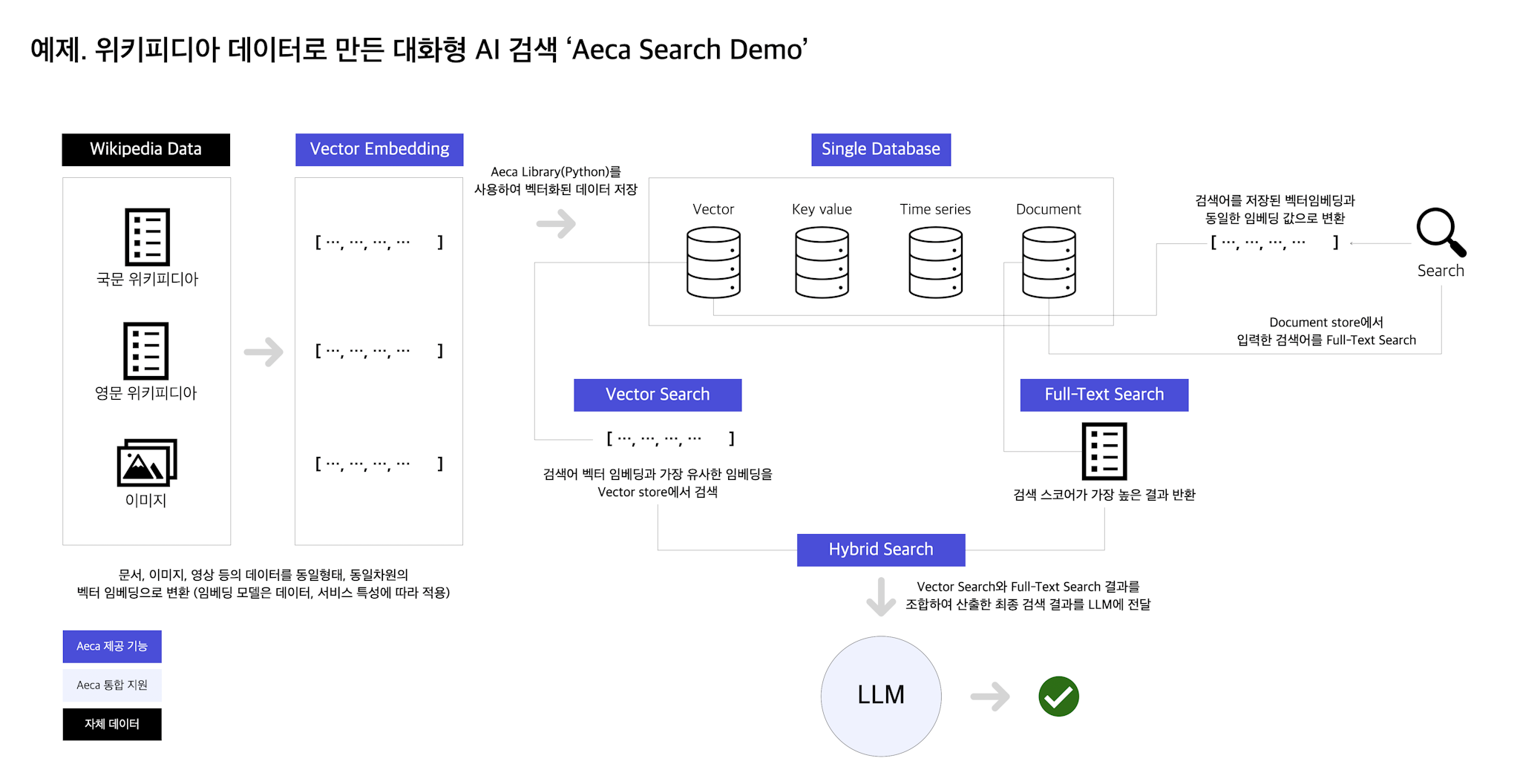
Aeca를 활용해 위키피디아 백과사전을 대상으로 Q&A 시스템을 구축한 사례를 살펴보도록 하겠습니다. 먼저 아래 4가지 과정으로 구분할 수 있습니다.
- 원본데이터를 벡터임베딩으로 변환
- 벡터임베딩 저장
- 검색어를 벡터임베딩으로 변환후 유사 임베딩 검색
- 검색결과를 LLM에 컨텍스트로 전달하여 답변
Case Study
원본데이터를 벡터임베딩으로 변환
위키피디아 영문, 한글데이터를 위키홈페이지 에서 다운로드합니다.
위의 원본 문서데이터를 벡터임베딩으로 변환합니다. 임베딩으로 변환하기 위해서 SentenceTransformer의 "paraphrase-multilingual-mpnet-base-v2" 모델을 사용하였으며, 모델의 Vector dimension은 782차원 입니다. 문서데이터를 벡터임베딩으로 변환할 때 벡터화 단위를 결정해야 합니다. 개별단위문서, 문서페이지, 문단단위로 벡터화 할 수 있으며, 여기서는 문단 단위로 벡터임베딩을 생성하였습니다.
이렇게 변환된 벡터임베딩의 개수는 영문 약 3.4억개, 한글 1,700만개 입니다.
| 영문 위키피디아 | 한글 위키피디아 | |
|---|---|---|
| 벡터 차원수 | 782 | 782 |
| 벡터임베딩 개수 | 약 3억 4천만개 | 약 1,700만개 |
| 벡터임베딩 용량 | 890GB | 170GB |
벡터임베딩을 Aeca에 저장
이제 생성된 벡터임베딩을 벡터데이터베이스에 저장해야 합니다. 저장 대상파일의 스키마는 문단 ID, 문단 원본내용, 해당 문단의 벡터임베딩입니다. 로컬 랩탑에 설치된 Aeca를 Python에서 import하였습니다. Cogncia의 Python SDK는 데이터의 저장 검색을 쉽게하기 위한 다양한 라이브러리를 제공합니다.
channel = aeca.Channel("localhost", 10080)
다음으로 Aeca가 제공하는 데이터모델 중 하나인 DocumentDB를 호출하여 벡터임베딩을 저장합니다.
doc_db = aeca.DocumentDB(channel) doc_db.insert("Example.K-GAAP", docs)
위 과정에 사용한 코드는 단 25줄에 불과합니다.
import pickle import aeca def main(): with open("data/wiki.pk", "rb") as fp: content = pickle.load(fp) docs = [] for sentence_id, line, embed in content: if len(line) < 10: continue doc = { "sentence_id": sentence_id, "sentence": line, "sentence_embed": embed.tolist(), } docs.append(doc) channel = aeca.Channel("localhost", 10080) doc_db = aeca.DocumentDB(channel) doc_db.insert("Example.wiki", docs) if __name__ == "__main__": main()
검색어를 벡터임베딩으로 변환후 유사 임베딩 검색
Congica에 저장된 위키피디아 백과사전을 대상으로 검색하여 관련된 문서를 찾아야 합니다. 관련성이 높은 결과를 찾기 위해 벡터검색과 Full text search를 모두 이용한 하이브리드 검색을 사용하였습니다.
벡터검색을 위해서는 입력된 질문, 검색어등을 벡터임베딩으로 변환해야합니다. 이 때 저장된 데이터에 사용한 Transformer 모델과 동일한 모델을 사용해 검색어 임베딩을 만들어야 합니다. 그리고 검색어 임베딩과 가장 유사한 임베딩을 찾은 후 Full text search 결과를 함께 고려하여 반환한 검색결과의 원본데이터를 LLM에 전달합니다. 유사한 벡터임베딩을 검색하는 알고리즘은 ANN 등이 있는데, 이 사례에서는 HNSW 알고리즘을 사용하였습니다.
위 과정에 사용한 코드 입니다.
import aeca def main(): channel = aeca.Channel("localhost", 10080) doc_db = aeca.DocumentDB(channel) model = aeca.SentenceTransformerEncoder( channel, "paraphrase-multilingual-mpnet-base-v2" ) query = input("> ") query_embed = model.encode(query) dtypes = {"sentence_embed": "json", "_meta": "json"} query_embed = ", ".join([str(v) for v in query_embed[0].tolist()]) search_query = { "$search": { "query": ( f"(sentence:({query}))^0.2 or" f" (sentence_embed:[{query_embed}])^20" ), "limit": 1000, "min_score": 0.7, }, "$hint": "sk_fts", } df = doc_db.find("Example.wiki", search_query, dtypes=dtypes) print(df) sentence_id = int(df["sentence_id"][0]) context_query = { "sentence_id": {"$gte": sentence_id - 2, "$lte": sentence_id + 18}, "$project": ["sentence_id", "sentence"], "$sort": ["sentence_id"], } df = doc_db.find("Example.wiki", context_query, limit=1000) print(len(df)) print(df) if __name__ == "__main__": main()
검색결과를 LLM에 컨텍스트로 전달하여 답변
검색결과의 원본데이터를 LLM에 전달합니다. LLM 전달받은 텍스트를 기반으로 질문에 적합한 답변을 생성합니다. 아래는 위 과정을 그림으로 나타낸 것입니다.
결과 살펴보기
이제 결과를 한 번 살펴 볼까요? 아래 2개의 질문을 하고 ChatGPT 와 비교해보겠습니다.
- 전 세계에는 몇 개의 국가가 있어?
- 대한민국 최초의 검색엔진은?
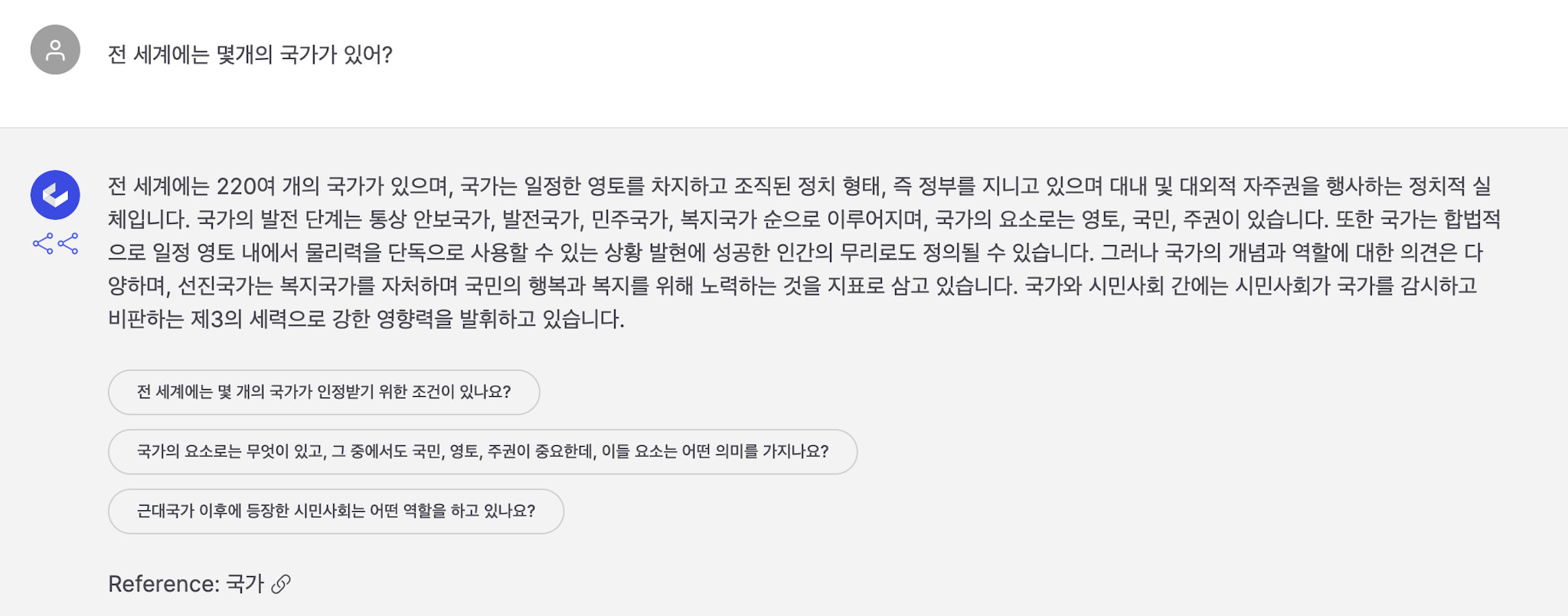
전 세계에는 몇 개의 국가가 있어?
| LLM with Aeca | ChatGPT |
|---|---|
| 전 세계에는 220여 개의 국가가 있으며, 국가는 일정한 영토를 차지하고 조직된 정치 형태, 즉 정부를 지니고 있으며 대내 및 대외적 자주권을 행사하는 정치적 실체입니다. 국가의 발전 단계는 통상 안보국가, 발전국가, 민주국가, 복지국가 순으로 이루어지며, 국가의 요소로는 영토, 국민, 주권이 있습니다. 또한 국가는 합법적으로 일정 영토 내에서 물리력을 단독으로 사용할 수 있는 상황 발현에 성공한 인간의 무리로도 정의될 수 있습니다. 그러나 국가의 개념과 역할에 대한 의견은 다양하며, 선진국가는 복지국가를 자처하며 국민의 행복과 복지를 위해 노력하는 것을 지표로 삼고 있습니다. 국가와 시민사회 간에는 시민사회가 국가를 감시하고 비판하는 제3의 세력으로 강한 영향력을 발휘하고 있습니다. Reference: 국가 - 위키백과, 우리 모두의 백과사전 | 2021년 9월을 기준으로 전 세계에는 195개의 독립 국가가 있습니다. 하지만 국제 정치와 지리적 변화로 인해 국가의 수는 변할 수 있으므로, 현재의 숫자가 항상 정확하지는 않을 수 있습니다. 국가의 정체성과 인정은 국제사회와 국제 기구에 따라 다를 수 있으며, 새로운 국가가 독립적으로 선포되거나 국가의 정체성이 변경될 때마다 국가 수가 조금씩 변할 수 있습니다. |
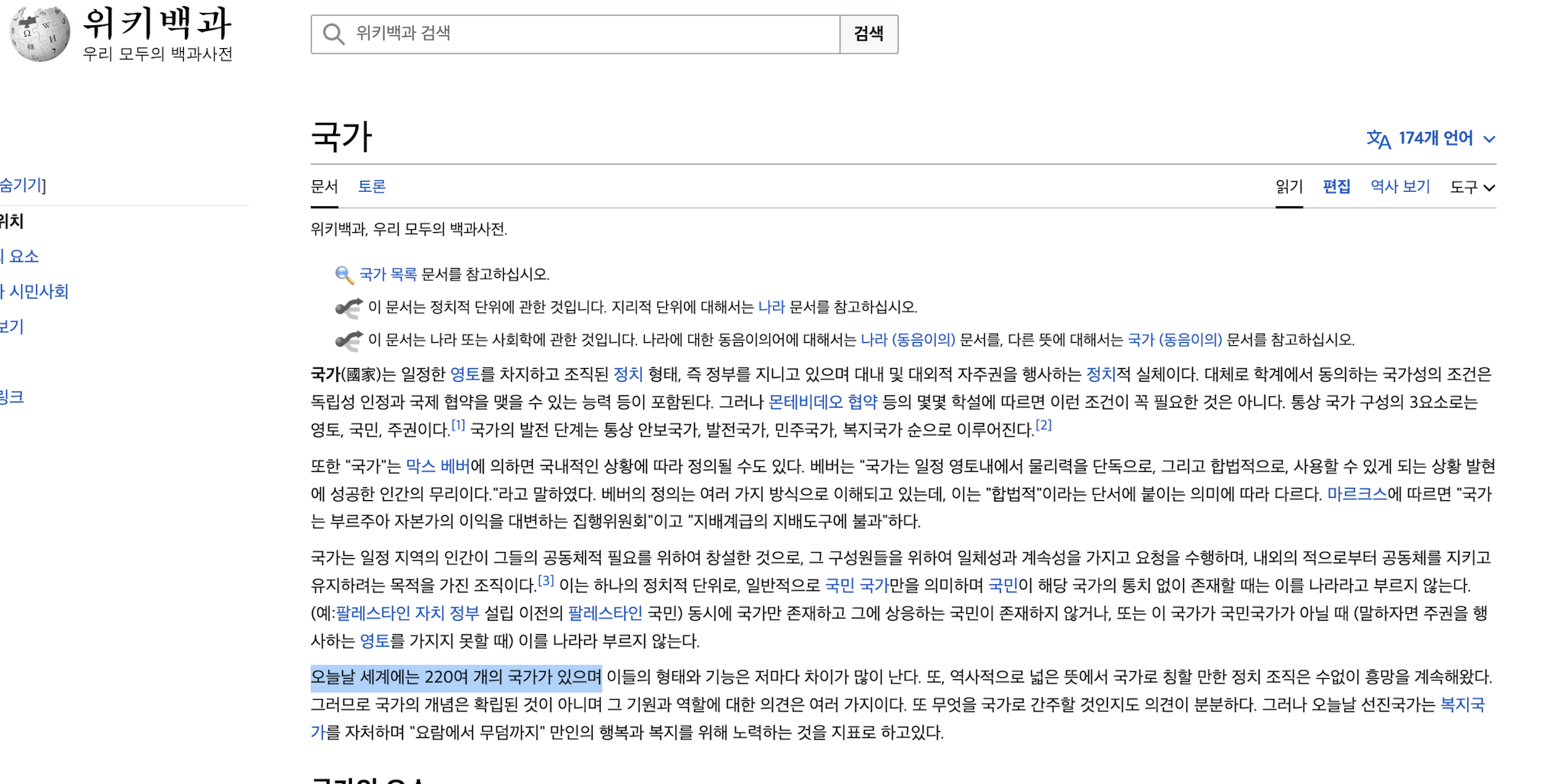
벡터데이터베이스를 사용한 경우에서는 위키피디아의 “국가” 문서를 검색한 다음 LLM이 해당 문서의 내용을 토대로 답변을 생성해줍니다. 또한 원본 문서를 함께 제공하여 전 세계에는 220여개의 국가가 있는 것을 해당 문서에서 확인 할 수 있습니다.
ChatGPT는 2021년 9월을 기준으로 195개의 독립국가가 있다는 답변을 제공하는데, 답변의 구체적인 근거를 제공하지는 않습니다.
대한민국 최초의 검색엔진은?
| LLM with Aeca | ChatGPT |
|---|---|
| 대한민국 최초의 인터넷 검색 엔진은 1995년에 충남대 대학원생인 김영렬에 의해 개발된 코시크입니다. 코시크는 한글 검색 엔진으로, 인터넷 상에서 사용자의 요청에 맞게 한글 정보를 찾아주는 소프트웨어나 서비스입니다. 이후 1996년에는 까치네와 심마니, 그리고 1998년에는 네이버가 서비스를 시작하였습니다. 이 정보는 "매일경제신문"의 1996년 6월 20일자 기사를 참고한 것입니다. | 대한민국 최초의 검색 엔진은 "웹메이트"라는 검색 엔진입니다. 웹메이트는 1996년에 처음 출시되었으며, 그 당시에는 한국 웹 검색 엔진의 선두 주자로 많이 사용되었습니다. 이후에도 다양한 검색 엔진이 등장하면서 웹 검색 분야가 계속 발전해왔습니다. 현재 대한민국에서는 구글, 네이버, 다음 등 다양한 검색 엔진이 사용되고 있습니다. |
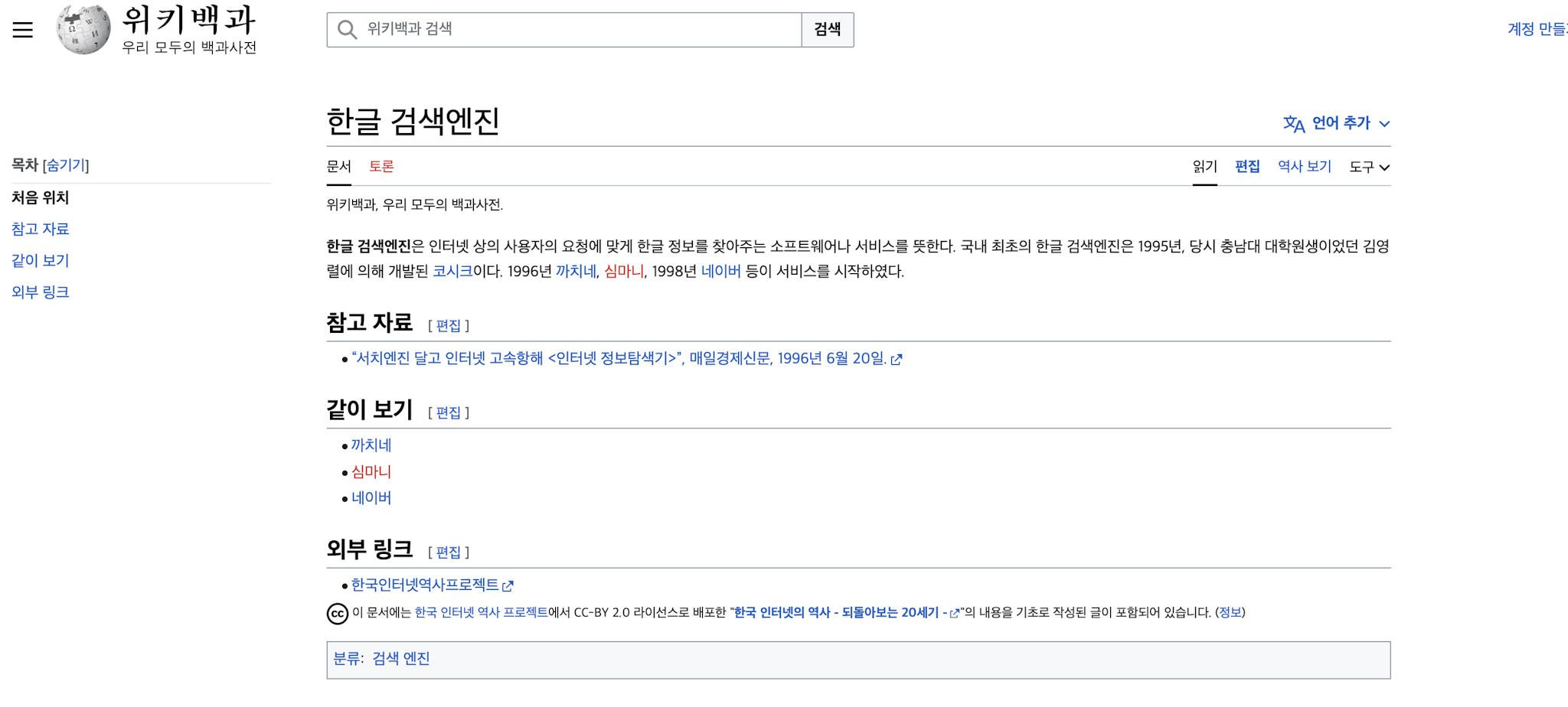
위키피디아를 대상으로 검색한 결과는 1995년에 개발된 코시크를 답변하는 반면, ChatGPT는 1996년 출시된 웹메이트라는 답변을 제공합니다. Aeca에서 답변과 제공된 원본문서를 확인해보았습니다. “한글검색엔진”이라는 페이지에서 1995년 코시크가 개발된 것을 확인 할 수 있습니다.
ChatGPT와 같이 LLM 만을 사용할 경우 사실과 다른 정보가 답변되거나, 답변의 근거를 확인 할 수 없는 문제가 있습니다. 그러나 벡터데이터베이스를 사용하면 LLM이 학습하지 않은 최신 정보에 대해서도 정확한 답변이 가능하고, 답변의 근거를 확인하여 신뢰성을 높일 수 있습니다.
응용사례 살펴보기
이 Case Study에서는 위키피디아 백과사전을 대상으로 하였으나, 모든 문서에 데이터에 대해 동일하게 적용 할 수 있습니다. 특히 아래와 같은 내부데이터는 LLM이 학습 할 수 없는 것들인데, 이를 Aeca에 저장하여 LLM과 함께 사용하면 질문에 적합한 답변을 빠르게 찾아 활용 할 수 있습니다.
| 데이터 | 활용방안 |
|---|---|
| 판례 및 최신법령 | 유사한 케이스를 빠르게 찾아 서면작성에 활용 할 수 있습니다. 특히 판결문 데이터는 구조화된 문서로 Hybrid 검색 적용시 극적인 퀄리티 향상을 기대 할 수 있습니다. |
| 회사내 커뮤니케이션 자료 | 슬랙과 같은 협업 툴에는 업무와 관련된 방대한 대화내용이 저장되어 있습니다. 벡터데이터베이스를 활용하여 과거에 어떤 방식으로 업무를 처리했는지, 어떤 의사결정을 내렸는지 빠르게 검토 할 수 있습니다. |
| 수많은 계약서 정보 | 회사가 보유한 수많은 계약서를 벡터화하여 저장 후 유사한 계약, 과거 계약정보를 찾을 수 있습니다. |
| 고객문의 내용 | 채널톡에 저장된 수많은 고객상담 내용을 빠르게 검색하여 고객 불편사항, 개선점을 도출하고, 상담과정을 자동화 할 수 있습니다. |